(Computer) Vision with Lost Glasses
Modelling how the brain deals with noisy input
![]()
Objective
Imagine you lost your spectacle and the world around you is completely blurred out. As you stumble around, you see a small animal walk towards you. Can you figure out what it is? Probably yes right?
In this situation, or in foggy/night-time conditions, visual input is of poor quality; images are blurred and have low contrast and yet our brains manage to recognize it. Is it possible to model the process? Does previous experience help?
Introduction
Computer vision is one of the main areas where Artificial Neural Networks are frequently deployed to classify images. How these networks deal with various aberrations in the images is an ongoing field of research.
In this project, we use the ASIRRA dataset that contains images of dogs and cats to test the binary classification efficiency of a downscaled AlexNet, one of the most famous Artificial Neural Network used in computer vision using cross-entropy as loss function, ADAM optimizer, and early stopping to prevent overfitting and minimize training duration.
This network is trained on different variations of the dataset which are pathophysiologically analogous to various visual distortions of the human visual system like full or partial color blindness, blurriness. We use gaussian noise (of radius 2 and 5) and decrease the resolution to 64x64 pixels to simulate vision with lost glasses, color removal as an analog for partial color blindness, greyscale for full-color blindness, and some additional artificial errors such as salt and pepper, and speckle.
We also see the heat activation maps of the various error types to get a visual idea of the feature extraction being done in the network for various errors. We expect to see differences in accuracy and the number of epochs taken to reach suitable accuracy for different errors and understand why this Artificial Neural Network may perform better on specific variations.
The Asirra dataset
The CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) or HIP (Human Interactive Proof) challenge is the motivation behind the creation of this dataset.
Asirra (Animal Species Image Recognition for Restricting Access) is a HIP that works by asking users to identify photographs of cats and dogs. This task is difficult for computers, but studies have shown that people can accomplish it quickly and accurately.
Reference: Dataset can be found here (https://www.kaggle.com/c/dogs-vs-cats)
Project Model
- We use ASIRRA dataset containing images of cats and dogs as a binary classification problem.
- We loaded the dataset with clear images and gaussian blur with radius 5 and 2.
- Introduce some other errors that are biologically plausible such as -
- Greyscale for full color blindness
- Individual color removal for partial color blindness
- Synthetic errors such as salt and pepper, and speckle
- Downscaled Alexnet (by 2) and 64x64 images to increase speed.
- ADAM optimizer along with cross-entropy as loss function.
- Regulariser - Early stopping
Deep Learning Models of the Ventral Visual Stream
 Lets try to model the visual categorisation task using AlexNet as model of the ventral visual stream.
Lets try to model the visual categorisation task using AlexNet as model of the ventral visual stream.
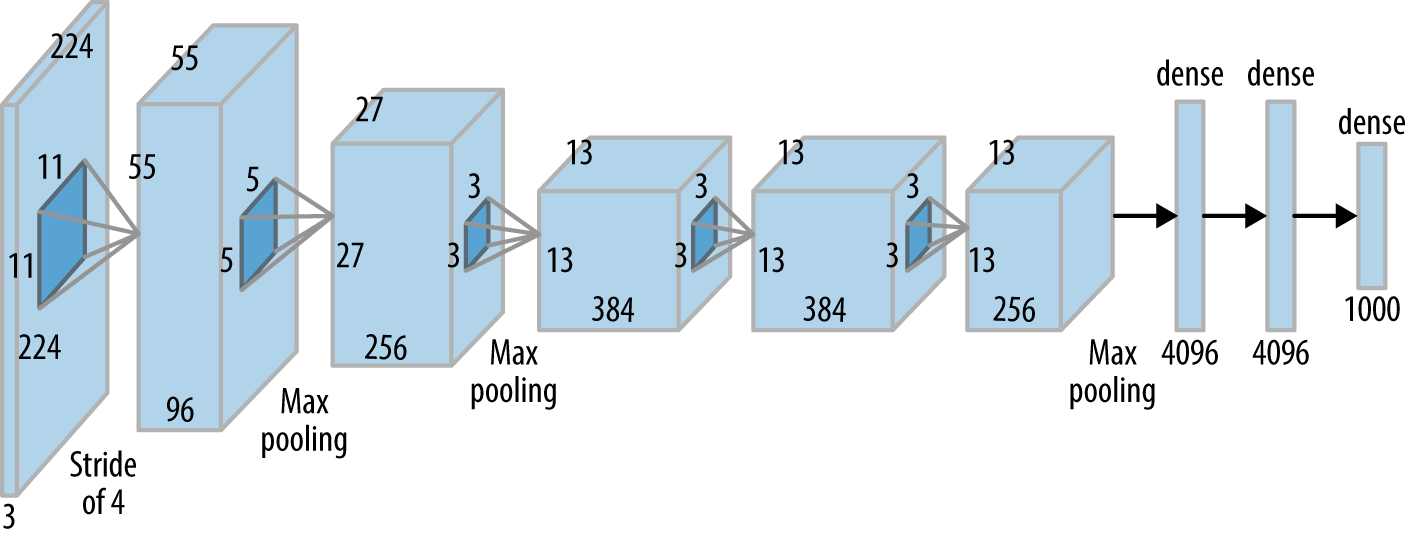
Create Test Neural Network (AlexNet, 2012 with Batch Normalization and a downscaling factor)
We add Batch Normalization to make training faster and add a scaling factor to test the architechture in a relatively smaller and computationally feasible model. The parameter downscale scales down the number of channels in the network by the factor given by the value. For computational feasibility on Google Colab we use an Alexnet downscaled by a factor of 2.
Hypothesis
-
H0: The visual system model with experience of seeing images without blur will have a much better performance on the blurry images out of the box compared to the naive learner.
-
H1: The visual system model with experience of seeing images without blur will have a better performance on the blurry images after training compared to the naive learner.
Training patterns
- Naive learner
Trains directly on specific errors.A Naive learner model looks at only the blurry images and tries to learn the difference between a cat and a dog
- Expert Experienced learner
First trains on clear images and then on specific errors.A Expert learner model first learns to look at less noisy images of cats and dogs and then try to distinguish the blurry images. It then learns on blurry images and tries to understand the difference between a cat and a dog
- Intermediate layer outputs
Shows how V1, V2, and V4 layers look for specific images.Example Images
- Gaussian Blur 5

- Gaussian Blur 2

- Color Removal

- Speckle Noise

- Salt and Pepper Noise

Accuracy
Gaussian Noise - radius 5
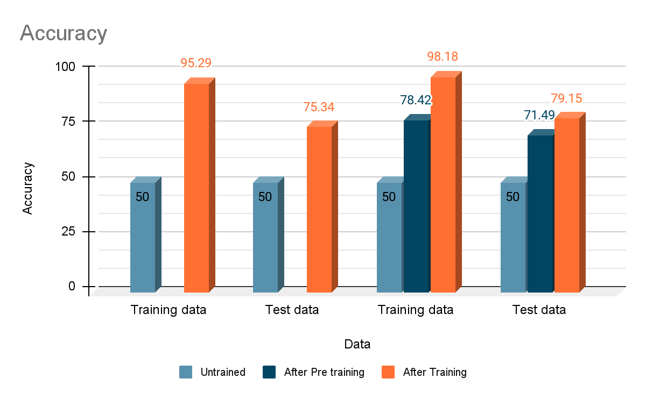
Blue color deletion
Intermediate layer output
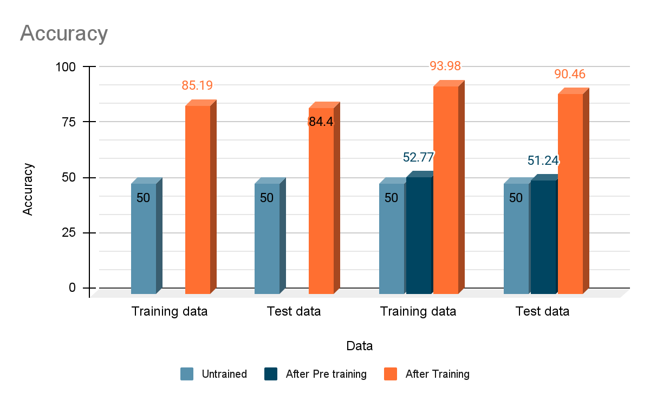
Blue color blindness - intermediate layer output
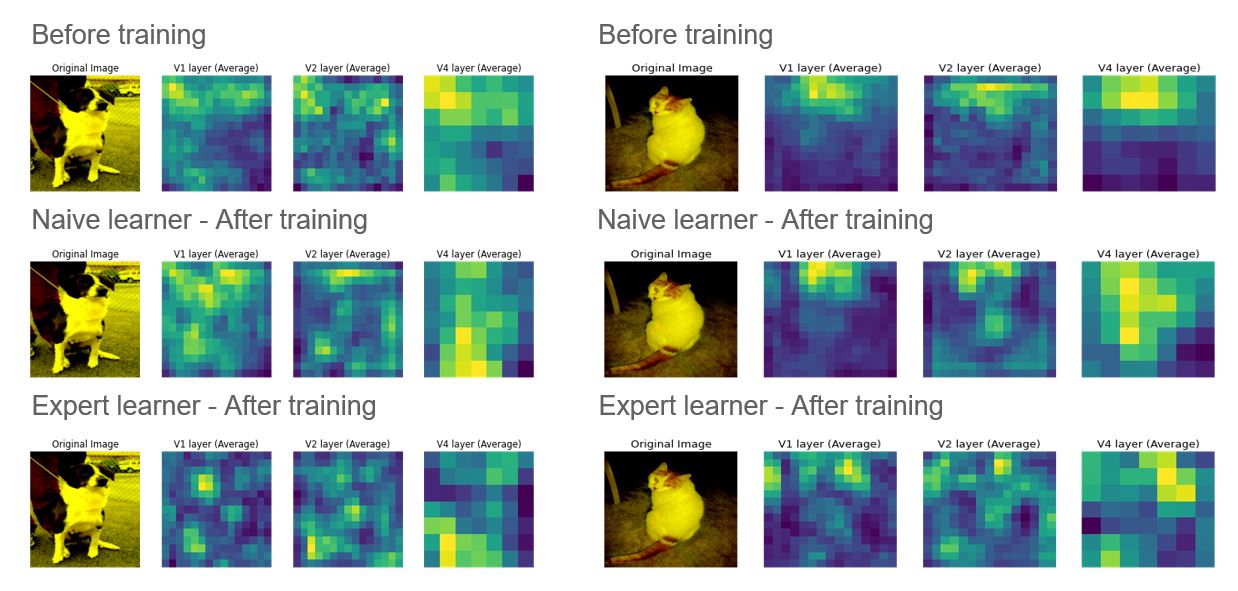
- Over training, the naive model seems to have learnt more complex features as apparent from the intermediate layer outputs.
- Clearly, the network output is only somewhat similar between pretraining and training. The differences seem to suggest that the process of learning over blurred images did change the features the network focused which probably contibuted to improved response to blurry images.
Performance
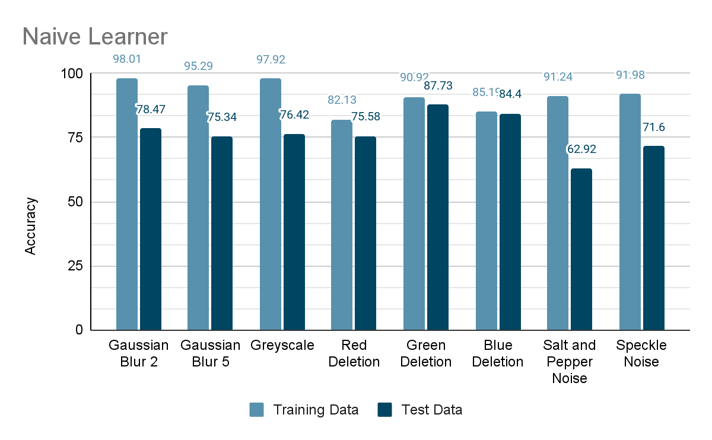
Performance of Naive Learner on different noise
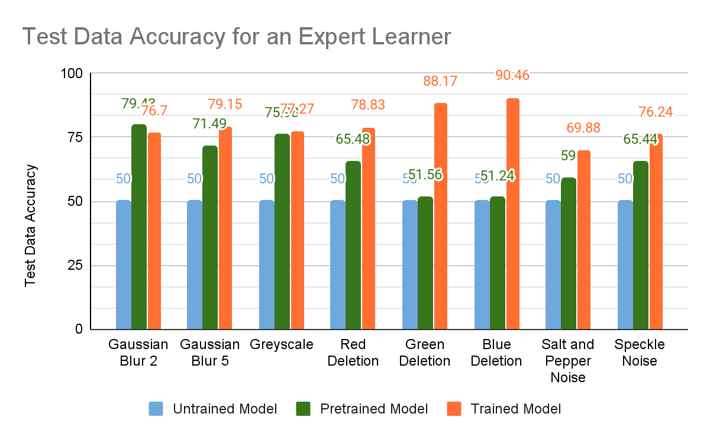
Performance of Expert Learner on different noise
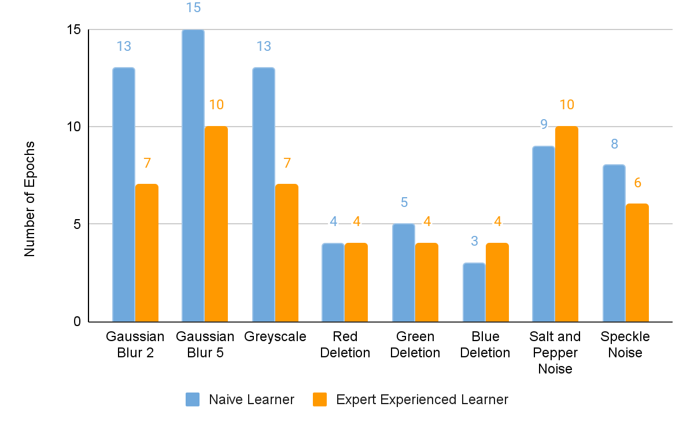
Naive Learner vs Expert Learner
Conclusion
- The model of the visual system has a hard time at the beginning to distinguish between blurry cats and dogs even after having seen images of cats and dog before!
- Trained models performed better than untrained ones!
- For Gaussian noise and Grayscale images -
- Good accuracy on Pretrained Model
- Less number of epochs for training a pre-trained model
- Poor performance on single color deletion unless trained